작년 하반기에 수강한 디비안 SQLP과정 교육 중 쿼리변환과 관련하여 The Logical Optimizer 책을 소개받았다. 쿼리변환만을 주제로 한 두꺼운 책 한권이 있을정도로 쿼리변환은 튜닝을 위해 꼭 알아둬야할 개념이라는 것이었다. 나중에 한번 읽어봐야지 했던 책이었는데 DB 관련 서적은 없는게 없는 우리 사무실에서 발견! 이거는 지금 당장 읽으라는 신의 계시인가! SQLP 취득 후 소홀히 했던 튜닝공부를 다시 시작해보려한다.
모든 책의 1장이 그러하듯 이 책에서도 1장은 쿼리변환 Query Transformation 의 개념에 대해 소개하고있다. 이 책에서는 logical optimizer에 대해 설명하며 logical 옵티마이저는 쿼리 자체를 변경하는 것이고, physical optimizer는 변경된 sql을 물리적으로 최적화 하는 것이기때문에 logical 옵티마이저에 종속적인 개념이다. 옵티마이저 컴포넌트에는 쿼리변환기, 비용계산기, 플랜생성기가 있고 앞으로 공부하게될 쿼리변화기에 주목해보자.
SQL을 재작성하는 옵티마이저의 목적은 성능향상! 원칙적으로 변환쿼리와 원본쿼리가 의미하는바가 같아야 한다. 책에서 예시로 든 불필요한 distinct 제거에 대한 예제를 적어본다.
/*테이블 생성*/
create table t1 (id varchar(10), name varchar(50));
/*임의 데이터 insert*/
insert into t1
select rownum, 'test' || rownum
from dual
connect by level<= 10;
commit;
/*unique 인덱스 없는 경우 실행계획*/
select distinct id from t1;
/*unique 인덱스 생성 후 실행계획*/
--drop index idx_01;
create unique index idx_01 on t1 (id);
select distinct id from t1;
책에서는 오라클11 버전으로 작성되어있으나 내 pc에 설치된 티베로에서 실행계획을 확인해보았다. 책에서 설명한 내용과 같이 distint문이 작성된 동일 쿼리라 할지라도 unique index 가 있는 경우는 불필요한 distinct문에 해당하기 때문에 실행계획에 DISTINCT (HASH) 부분이 생략된다.
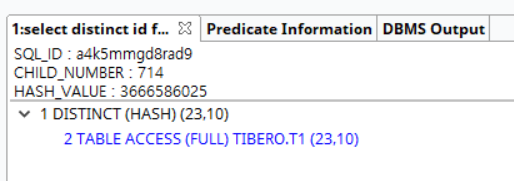
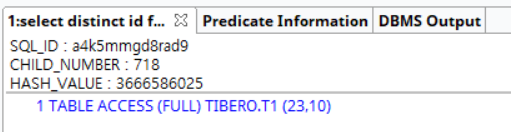
현업에서 마주하는 다양한 쿼리 스타일이 있지만 불필요하게 DISTINCT를 남발하는 쿼리는 업무파악을 힘들게 하는 요소중 하나이다. 위 상황처럼 모델링이라도 잘되어있어 unique index가 만들어져있으면 옵티마이저가 변환이라도 해줄텐데 보통은 모델링마저 눈물겨운 경우가 많다. select count(distinct 컬럼) from 테이블 건수와 select count(*) from 테이블 건수를 비교하여 같은경우 업무단에 문의하곤 했는데 더 좋은 방법을 알게되면 여기 다시 남겨야겠다.
'IT성장일기' 카테고리의 다른 글
| [IT성장일기]2024년 DB엔지니어 회고록 (0) | 2025.01.06 |
|---|---|
| [교육/SQL튜닝]조인의 원리와 활용 (1) | 2023.11.27 |
| [SQLP/시험후기]49회 SQLP 실기1번 문제 (0) | 2023.09.14 |
| [친절한SQL튜닝/온라인스터디]인덱스 튜닝 (0) | 2023.08.07 |
| [스터디/친절한SQL튜닝]소트튜닝 (0) | 2023.08.04 |


